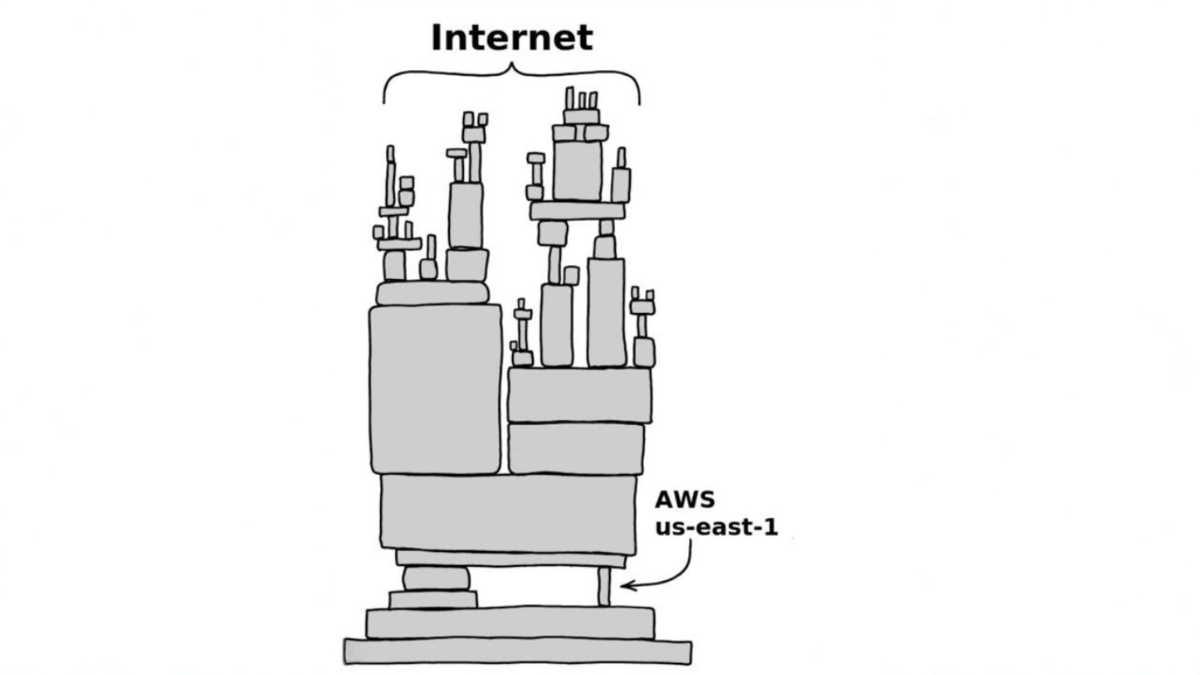
Incidente na região US-EAST-1, a mais crítica da Amazon, expôs a dependência sistêmica de mais de 500 empresas em um único provedor, em um caos que durou quase um dia inteiro.
Se a sua internet parecia “quebrada” nesta segunda-feira (20), você não estava sozinho. O que começou como uma manhã de instabilidade em alguns aplicativos se transformou em um apagão digital em cascata que paralisou setores inteiros da economia global. O culpado: uma falha massiva na Amazon Web Services (AWS), a maior provedora de computação em nuvem do mundo e a infraestrutura invisível que sustenta uma parcela colossal da internet moderna.
O caos foi sentido em escala global. No Brasil, gigantes como Mercado Livre, PicPay, iFood, OLX e até o sistema Pix apresentaram instabilidade severa. Nos Estados Unidos e Europa, a pane derrubou jogos como Fortnite e Roblox, plataformas de trabalho como Trello e Adobe, e até mesmo os sistemas de check-in de companhias aéreas como a Delta e a United Airlines, causando atrasos e filas em aeroportos.
A própria Amazon viu seus serviços, como a assistente Alexa e o Prime Video, falharem. A instabilidade começou nas primeiras horas da manhã de segunda-feira e só foi completamente mitigada por volta das 20h (horário de Brasília), após um dia inteiro de caos e prejuízos incalculáveis.
O Que é a AWS e Por Que o Mundo Parou?
Para o leitor leigo, é crucial entender o que é a AWS. Pense na internet como uma cidade gigantesca. A Amazon Web Services é a empresa que detém a maior parte dos “terrenos” e da “infraestrutura” dessa cidade. Ela aluga poder de computação, armazenamento de dados, bancos de dados e dezenas de outros serviços para que mais de 500 empresas, de startups a gigantes, construam suas “fábricas” (aplicativos e sites).
O problema é que a AWS, embora global, possui “regiões” (conjuntos de data centers). A falha de ontem ocorreu na região US-EAST-1, localizada no norte da Virgínia, EUA. Esta não é apenas uma região; é a mais antiga, a maior e, historicamente, a mais importante da AWS. Muitas empresas, mesmo globais, concentram parte crítica de suas operações lá, tornando-a um ponto único de falha sistêmico.
A Causa do Apagão: O “Catálogo Telefônico” da Nuvem Quebrou
Em seu comunicado oficial, divulgado no painel AWS Health Status, a Amazon foi técnica: “Determinamos que o evento foi resultado de problemas de resolução de DNS para os pontos de extremidade do serviço regional do DynamoDB“.
Vamos traduzir o “tecniquês”:
- DNS (Domain Name System): É a “lista telefônica” da internet. Como explica Arthur Igreja, especialista em Tecnologia e Inovação, “é quando digitamos um nome no navegador e acessamos um número de IP. E quando tem uma indisponibilidade de DNS, os aplicativos não conseguem acessar as suas bases”.
- DynamoDB: É um dos serviços de banco de dados mais populares da AWS. Pense nele como um “arquivo central” gigantesco e ultrarrápido onde aplicativos guardam informações vitais (dados de login, listas de produtos, salvar jogos, etc.).
O que aconteceu foi: A “lista telefônica” (DNS) que dizia aos aplicativos onde encontrar seus “arquivos centrais” (DynamoDB) simplesmente quebrou dentro da região US-EAST-1. O resultado foi um efeito dominó: o aplicativo do Mercado Livre tentava encontrar a lista de produtos, mas não conseguia; o PicPay tentava acessar os dados da conta, mas falhava; o Fortnite não conseguia carregar os dados do jogador.
O efeito em cascata foi monitorado pela plataforma Downdetector, que registrou picos de reclamações simultâneas para centenas de serviços que, aparentemente, não tinham relação entre si, mas compartilhavam a mesma fundação defeituosa na AWS.

O Mapa da Crise: Quem Foi Mais Afetado?
A lista de mais de 500 empresas afetadas mostra a profundidade da dependência da AWS:
- E-commerce e Pagamentos (Brasil): Mercado Livre, Mercado Pago, PicPay, iFood, OLX, Wellhub (antigo Gympass), TotalPass.
- Setor Financeiro (Global): Coinbase, Robinhood, Venmo e corretoras de criptomoedas.
- Entretenimento e Jogos: Fortnite, Roblox, Clash Royale, Clash of Clans, Epic Games Store, Netflix, Prime Video.
- Trabalho e Comunicação: Zoom, Slack, Trello, Reddit, Adobe, Canva.
- Serviços Críticos (EUA): Delta Air Lines, United Airlines (sistemas de reserva e check-in), aplicativo do McDonald’s.
Análise Rarduér: A Perigosa Centralização da Nuvem Descentralizada
A ironia da computação em nuvem é que ela vende uma ideia de resiliência e descentralização (a “nuvem” etérea), quando na prática, ela centralizou um terço de toda a infraestrutura da internet mundial nas mãos de um único provedor: a Amazon.
Este apagão não é um caso isolado. Ele lembra a falha massiva do software CrowdStrike em 2024, que também paralisou companhias aéreas e serviços globais. Como argumentou Arthur Igreja, esse tipo de falha “não poderia ocorrer”, pois os principais requisitos da nuvem são “confiabilidade e disponibilidade”.
O incidente expõe que, apesar de toda a tecnologia de redundância, a complexidade da infraestrutura da AWS atingiu um ponto em que uma falha em um serviço central, como o DNS do DynamoDB, em uma única região, é suficiente para causar um terremoto digital global.
Para o consumidor final, a lição foi de paciência. Para as mais de 500 empresas afetadas, a segunda-feira (20) foi um dia de prejuízos milionários e uma reavaliação forçada sobre o risco de colocar todos os “ovos digitais” na mesma cesta, mesmo que seja a cesta mais robusta do mundo. A Amazon, por sua vez, enfrenta agora uma enorme pressão para explicar como seu sistema mais crítico falhou de forma tão espetacular.
Por Diogo Neves, Redator Especializado em Tecnologia – Rarduér


